When working with biodiversity data, it is important to verify taxonomic names with an authoritative list and correct any out-of-date names or names with typos. The ‘APCalign’ package simplifies this process by:
- Accessing up-to-date taxonomic information from the Australian Plant Census and the Australia Plant Name Index.
- Aligning authoritative names to your taxonomic names using our fuzzy matching algorithm
- Updating your taxonomic names in a transparent, reproducible manner
Installation
The latest version of ‘APCalign’ should be available on CRAN and can
be installed using install.packages("APCalign").
You can alternatively install the current developmental version using
Alternatively, our ShinyApp, is available at unsw.shinyapps.io/APCalign-app
To demonstrate how to use ‘APCalign’, we will use an example dataset
gbif_lite which is documented in
?gbif_lite
dim(gbif_lite)
#> [1] 129 7
gbif_lite |> print(n = 6)
#> # A tibble: 129 × 7
#> species infraspecificepithet taxonrank decimalLongitude decimalLatitude scientificname verbatimscientificname
#> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr>
#> 1 Tetratheca ciliata <NA> SPECIES 145. -37.4 Tetratheca ci… Tetratheca ciliata
#> 2 Peganum harmala <NA> SPECIES 139. -33.3 Peganum harma… Peganum harmala
#> 3 Calotis multicaulis <NA> SPECIES 115. -24.3 Calotis multi… Calotis multicaulis
#> 4 Leptospermum triner… <NA> SPECIES 151. -34.0 Leptospermum … Leptospermum trinervi…
#> 5 Lepidosperma latera… <NA> SPECIES 142. -37.3 Lepidosperma … Lepidosperma laterale
#> 6 Enneapogon polyphyl… <NA> SPECIES 129. -17.8 Enneapogon po… Enneapogon polyphyllus
#> # ℹ 123 more rowsRetrieve taxonomic resources
The first step is to retrieve the entire APC and APNI name databases
and store them locally as taxonomic resources. We achieve this using
load_taxonomic_resources().
There are two versions of the databases that you can retrieve with
the stable_or_current_data argument. Calling:
-
stablewill retrieve the most recent, archived version of the databases from our GitHub releases. This is set as the default option. -
currentwill retrieve the up-to-date databases directly from the APC and APNI website.
Note that the databases are quite large so the initial retrieval of
stable versions will take a few minutes. Once the taxonomic
resources have been stored locally, subsequent retrievals will take less
time. Retrieving current resources will always take longer
since it is accessing the latest information from the website. Check out
our Resource
Caching article to learn more about how the APC and APNI databases
are accessed, stored and retrieved.
# Benchmarking the retrieval of `stable` or `current` resources
stable_start_time <- Sys.time()
stable_resources <- load_taxonomic_resources(stable_or_current_data = "stable")#> Loading resources into memory...
#>
=========================================
===================================================================================
============================================================================================================================
#> ...done
stable_end_time <- Sys.time()
current_start_time <- Sys.time()
current_resources <- load_taxonomic_resources(stable_or_current_data = "current")#> Loading resources into memory...
#>
=========================================
===================================================================================
============================================================================================================================
#> ...done
current_end_time <- Sys.time()
# Compare times
stable_end_time - stable_start_time
#> Time difference of 6.69976 secsFor a more reproducible workflow, we recommend specifying the exact
stable version you want to use.
resources <- load_taxonomic_resources(stable_or_current_data = "stable", version = "2024-10-11")#> Loading resources into memory...
#>
=========================================
===================================================================================
============================================================================================================================
#> ...doneAlign and update plant taxon names
Now we can query our taxonomic names against the taxonomic resources
we just retrieved using create_taxonomic_update_lookup().
This all-in-one function will:
- Align your taxonomic names to APC and APNI using our matching
algorithms
- Update names to an APC-accepted species or infraspecific name
whenever possible.
- Return a suggested name for all names, defaulting to an
accepted_namewhen available, and otherwise providing an APNI name or a name where only a genus-level alignment is possible.
If you would like to learn more about each of these step, take a look at the section Closer look at name alignment and updating with ‘APCalign’
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following object is masked from 'package:testthat':
#>
#> matches
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
updated_gbif_names <- gbif_lite |>
pull(species) |>
create_taxonomic_update_lookup(resources = resources)
#> Checking alignments of 121 taxa
#> -> of these 112 names have a perfect match to a scientific name in the APC.
#> Alignments being sought for remaining names.
updated_gbif_names |>
print(n = 6)
#> # A tibble: 129 × 12
#> original_name aligned_name accepted_name suggested_name genus taxon_rank taxonomic_dataset taxonomic_status
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 Tetratheca ciliata Tetratheca cilia… Tetratheca c… Tetratheca ci… Tetr… species APC accepted
#> 2 Peganum harmala Peganum harmala Peganum harm… Peganum harma… Pega… species APC accepted
#> 3 Calotis multicaulis Calotis multicau… Calotis mult… Calotis multi… Calo… species APC accepted
#> 4 Leptospermum trinervium Leptospermum tri… Leptospermum… Leptospermum … Lept… species APC accepted
#> 5 Lepidosperma laterale Lepidosperma lat… Lepidosperma… Lepidosperma … Lepi… species APC accepted
#> 6 Enneapogon polyphyllus Enneapogon polyp… Enneapogon p… Enneapogon po… Enne… species APC accepted
#> # ℹ 123 more rows
#> # ℹ 4 more variables: scientific_name <chr>, aligned_reason <chr>, update_reason <chr>, number_of_collapsed_taxa <dbl>The original_name is the taxon name used in your
original data. The aligned_name is the taxon name we used
to link with the APC to identify any synonyms. The
accepted_name is the currently, accepted taxon name used by
the Australian Plant Census. The suggested_name is the best
possible name option for the original_name.
Plant established status across states/territories
‘APCalign’ can also provide the state/territory distribution for established status (native/introduced) from the APC.
We can access the established status data by state/territory using
create_species_state_origin_matrix()
You can specify to include infrataxa (subspecies, varieties and
forms) using include_infrataxa = TRUE, or generate
statistics just for species using
include_infrataxa = FALSE.
# Retrieve status data by state/territory
status_matrix <- create_species_state_origin_matrix(resources = resources, include_infrataxa = TRUE)Here is a breakdown of all possible values for
origin
library(purrr)
#>
#> Attaching package: 'purrr'
#> The following object is masked from 'package:testthat':
#>
#> is_null
library(janitor)
#>
#> Attaching package: 'janitor'
#> The following objects are masked from 'package:stats':
#>
#> chisq.test, fisher.test
# Obtain unique values for establishment status
status_matrix |>
tidyr::pivot_longer(4:21) |>
filter(value != "not present") |>
distinct(value)
# value
# <chr>
# 1 native
# 2 naturalised
# 3 doubtfully naturalised
# 4 native and naturalised
# 5 formerly naturalised
# 6 presumed extinct
# 7 uncertain origin
# 8 native and uncertain origin
# 9 native and doubtfully naturalisedYou can also obtain the breakdown of species by established status
for a particular state/territory using
state_diversity_counts()
state_diversity_counts("NSW", resources = resources)
#> # A tibble: 7 × 3
#> origin state num_species
#> <chr> <chr> <table[1d]>
#> 1 doubtfully naturalised NSW 93
#> 2 formerly naturalised NSW 8
#> 3 native NSW 5968
#> 4 native and doubtfully naturalised NSW 2
#> 5 native and naturalised NSW 34
#> 6 naturalised NSW 1580
#> 7 presumed extinct NSW 8Using the established status data and state/territory information, we
can check if a plant taxa is a native using
native_anywhere_in_australia()
library(dplyr)
updated_gbif_names |>
sample_n(1) |> # Choosing a random species
pull(suggested_name) |> # Extracting this APC accepted name
native_anywhere_in_australia(resources = resources)
#> # A tibble: 1 × 2
#> species native_anywhere_in_aus
#> <chr> <chr>
#> 1 Lomandra longifolia nativeCloser look at name standardisation with ‘APCalign’
create_taxonomic_update_lookup is a simple, wrapper,
function for novice users that want to quickly check and standardise
taxon names. For more experienced users, you can take a look at the sub
functions match_taxa(), align_taxa() and
update_taxonomy() to see how taxon names are processed,
aligned and updated.
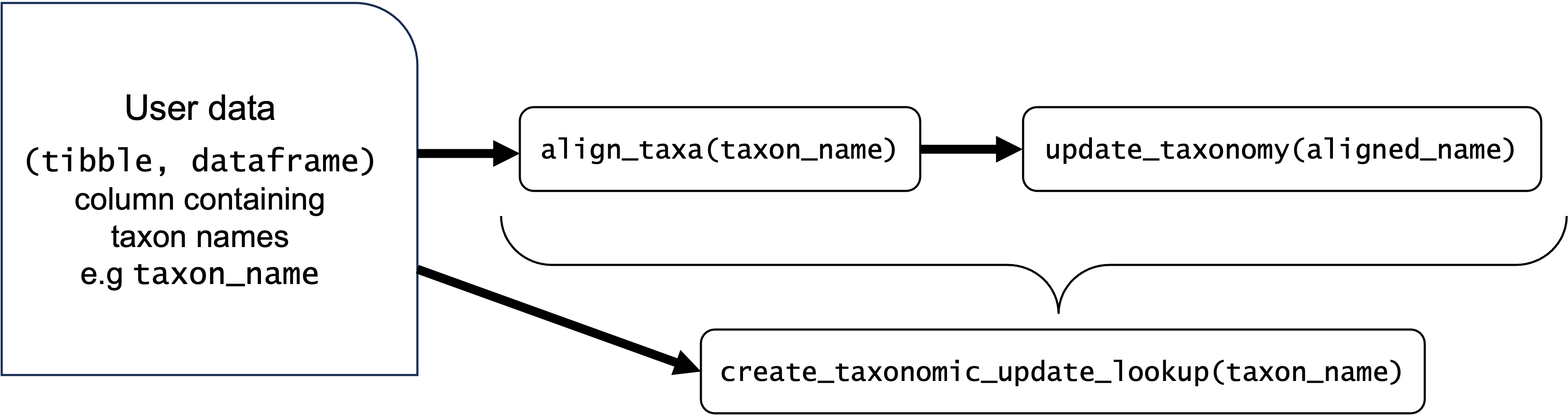
Aligning names to APC and APNI
The function align_taxa will:
- Clean up your taxonomic names
- The functions
standardise_names,strip_namesandstrip_names_extrastandardise infraspecific taxon designations and clean up punctuation and whitespaces
- The functions
- Find best alignment with APC or APNI to your taxonomic name using
our the function match_taxa
- A taxonomic name flows through a progression of 50
match algorithms until it is able to be aligned to a name on either
the APC or APNI list.
- These include exact and fuzzy matches.
Fuzzy matches are designed to capture small spelling mistakes and syntax
errors in phrase names.
- These include matches to the entire name string and matches on just
select words in the sequence.
- The sequence of matches has been carefully curated to align names with the fewest mistakes.
- A taxonomic name flows through a progression of 50
match algorithms until it is able to be aligned to a name on either
the APC or APNI list.
- Determine the
taxon_rankto which the name can be resolved, based on its syntax.- For names that can only be resolved to genus, reformats the name to
offer a standardised
genus sp.name, with additional information/notes provided as part of the original name in square brackets, as inAcacia sp. [skinny leaves]orAcacia sp. [Broken Hill]
- For names that can only be resolved to genus, reformats the name to
offer a standardised
- Determine the
taxonomic_reference(APC or APNI) of each name-alignment.
Note that align_taxa does
not seek to update outdated taxonomy. That process occurs
during update_taxonomy process.
align_taxa instead aligns each name input to the closest
match amongst names documented by the APC and APNI.
library(dplyr)
aligned_gbif_taxa <- gbif_lite |>
pull(species) |>
align_taxa(resources = resources)
#> Checking alignments of 121 taxa
#> -> of these 112 names have a perfect match to a scientific name in the APC.
#> Alignments being sought for remaining names.
aligned_gbif_taxa |>
print(n = 6)
#> # A tibble: 129 × 7
#> original_name cleaned_name aligned_name taxonomic_dataset taxon_rank aligned_reason alignment_code
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 Tetratheca ciliata Tetratheca ciliata Tetratheca cil… APC species Exact match o… match_01c_acc…
#> 2 Peganum harmala Peganum harmala Peganum harmala APC species Exact match o… match_01c_acc…
#> 3 Calotis multicaulis Calotis multicaulis Calotis multic… APC species Exact match o… match_01c_acc…
#> 4 Leptospermum trinervium Leptospermum trinervium Leptospermum t… APC species Exact match o… match_01c_acc…
#> 5 Lepidosperma laterale Lepidosperma laterale Lepidosperma l… APC species Exact match o… match_01c_acc…
#> 6 Enneapogon polyphyllus Enneapogon polyphyllus Enneapogon pol… APC species Exact match o… match_01c_acc…
#> # ℹ 123 more rowsFor every aligned_name, align_taxa() will
provide a aligned_reason which you can review as a table of
counts:
library(janitor)
aligned_gbif_taxa |>
pull(aligned_reason) |>
tabyl() |>
tibble()
#> # A tibble: 6 × 4
#> `pull(aligned_gbif_taxa, aligned_reason)` n percent valid_percent
#> <chr> <int> <dbl> <dbl>
#> 1 Exact match of taxon name to an APC-accepted canonical name once punctuation and filler words… 118 0.915 0.929
#> 2 Exact match of taxon name to an APC-known canonical name once punctuation and filler words ar… 6 0.0465 0.0472
#> 3 Exact match of taxon name to an APNI-listed canonical name once punctuation and filler words … 1 0.00775 0.00787
#> 4 Exact match of the first two words of the taxon name to an APC-accepted canonical name (2024-… 1 0.00775 0.00787
#> 5 Exact match of the first word of the taxon name to an APC-accepted genus (2024-11-14) 1 0.00775 0.00787
#> 6 <NA> 2 0.0155 NAConfiguring matching precision and aligned output
There are arguments in align_taxa that allows you to
select which of the 50 matching algorithms are activated/deactivated and
the degree of fuzziness of the fuzzy matching function
-
fuzzy_matchesturns fuzzy matching on / off (it defaults toTRUE).
-
fuzzy_abs_distandfuzzy_rel_distcontrol the degree of fuzzy matching (they default tofuzzy_abs_dist = 3&fuzzy_rel_dist = 0.2).
-
imprecise_fuzzy_matchesturns imprecise fuzzy matching on / off (it defaults toFALSE; for true it is set tofuzzy_abs_dist = 5&fuzzy_rel_dist = 0.25).
-
APNI_matchesturns matches to the APNI list on/off (it defaults toTRUE).
-
identifierallows you to specify a text string that is added to genus-level matches, indicating the site, study, etc e.g.Acacia sp. [Blue Mountains]
Updating to APC-accepted names
update_taxonomy() uses the information generated by
align_taxa() to, whenever possible, update names to
APC-accepted names.
updated_gbif_taxa <- aligned_gbif_taxa |>
update_taxonomy(resources = resources)
updated_gbif_taxa |>
print(n = 6)
#> # A tibble: 129 × 21
#> original_name aligned_name accepted_name suggested_name genus family taxon_rank taxonomic_dataset taxonomic_status
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 Tetratheca ciliata Tetratheca … Tetratheca c… Tetratheca ci… Tetr… Elaeo… species APC accepted
#> 2 Peganum harmala Peganum har… Peganum harm… Peganum harma… Pega… Nitra… species APC accepted
#> 3 Calotis multicaulis Calotis mul… Calotis mult… Calotis multi… Calo… Aster… species APC accepted
#> 4 Leptospermum trinerv… Leptospermu… Leptospermum… Leptospermum … Lept… Myrta… species APC accepted
#> 5 Lepidosperma laterale Lepidosperm… Lepidosperma… Lepidosperma … Lepi… Cyper… species APC accepted
#> 6 Enneapogon polyphyll… Enneapogon … Enneapogon p… Enneapogon po… Enne… Poace… species APC accepted
#> # ℹ 123 more rows
#> # ℹ 12 more variables: taxonomic_status_aligned <chr>, aligned_reason <chr>, update_reason <chr>, subclass <chr>,
#> # taxon_distribution <chr>, scientific_name <chr>, taxon_ID <chr>, taxon_ID_genus <chr>, scientific_name_ID <chr>,
#> # canonical_name <chr>, row_number <dbl>, number_of_collapsed_taxa <dbl>Taxonomic resources used for updating names
The APC includes all previously recorded taxonomic names for a current taxon concept, designating the currently-accepted name as
taxonomic_status: accepted, while previously used or inappropriately used names for the taxon concept have alternative taxonomic statuses documented (e.g. taxonomic synonym, orthographic variant, misapplied).The APC includes a column
acceptedNameUsageIDthat links a taxon name with an alternative taxonomic status to the current taxon name, allowing outdated/inappropriately used names to be synced to their current name.
Note: Names listed on the APNI but absent from the APC are
those that are designated as taxonomic_dataset: APNI by
APCalign. These are names that are currently
unknown by the APC. Over time, this list shrinks, as
taxonomists link ever more occasionally used name variants to an
APC-accepted taxon. However, for now, names listed only on the APNI
cannot be updated
Name updates at different taxonomic levels
-
update_taxonomy()divides names into lists based on thetaxon_rankandtaxonomic_datasetassigned byalign_taxa, as each list requires different updating algorithms.
- Only taxonomic names that are designated as
taxon_rank = species/infraspecificandtaxonomic_dataset = APCcan be updated to an APC-accepted name.
- For all other taxa, it may be possible to align the genus-name to an
APC-accepted genus.
- For all taxa, a
suggested_nameis provided, selecting theaccepted_namewhen available, and otherwise thealigned_name, but with, if possible, an updated, APC-accepted genus name.
Taxonomic splits
Taxonomic splits refers to instances where a single taxon concept is subsequently split into multiple taxon concepts. For such taxa, when the
aligned_nameis the “old” taxon concept name, it is impossible to know which of the currently accepted taxon concepts the name represents.-
The function
update_taxonomyincludes an argumenttaxonomic_splits, offering three alternative outputs for taxon concepts that have been split.most_likely_speciesis the default value, and returns theaccepted_nameof the original taxon_concept; alternative names are documented in square brackets as part of the suggested name (Acacia aneura [alternative possible names: Acacia minyura (pro parte misapplied) | Acacia paraneura (pro parte misapplied) | Acacia quadrimarginea (misapplied)).return_allreturns all currently accepted names that were split from the original taxon_concept; this leads to an increase in the number of rows in the output table. (Acacia aneura, Acacia minyura and Acacia paraneura are each output as a separate row, each with a unique taxon_ID)collapse_to_higher_taxondeclares that for split names, there is no way to be certain about which accepted name is appropriate and therefore that the best possible match is at the genus level; noaccepted_nameis returned, thetaxon_rankis demoted togenusand the suggested name documents the possible species-level names in square brackets (Acacia sp. [collapsed names: Acacia aneura (accepted) | Acacia minyura (pro parte misapplied) | Acacia paraneura (pro parte misapplied)])
library(dplyr)
aligned_gbif_taxa |>
update_taxonomy(taxonomic_splits = "most_likely_species",
resources = resources) |>
filter(original_name == "Acacia aneura") # Subsetting Acacia aneura as an example
#> # A tibble: 1 × 21
#> original_name aligned_name accepted_name suggested_name genus family taxon_rank taxonomic_dataset taxonomic_status
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 Acacia aneura Acacia aneura Acacia aneura Acacia aneura [alter… Acac… Fabac… species APC accepted
#> # ℹ 12 more variables: taxonomic_status_aligned <chr>, aligned_reason <chr>, update_reason <chr>, subclass <chr>,
#> # taxon_distribution <chr>, scientific_name <chr>, taxon_ID <chr>, taxon_ID_genus <chr>, scientific_name_ID <chr>,
#> # canonical_name <chr>, row_number <dbl>, number_of_collapsed_taxa <dbl>
aligned_gbif_taxa |>
update_taxonomy(taxonomic_splits = "return_all",
resources = resources) |>
filter(original_name == "Acacia aneura") # Subsetting Acacia aneura as an example
#> # A tibble: 3 × 21
#> original_name aligned_name accepted_name suggested_name genus family taxon_rank taxonomic_dataset taxonomic_status
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 Acacia aneura Acacia aneura Acacia aneura Acacia aneura Acacia Fabace… species APC accepted
#> 2 Acacia aneura Acacia aneura Acacia minyura Acacia minyura Acacia Fabace… species APC accepted
#> 3 Acacia aneura Acacia aneura Acacia paraneura Acacia paraneura Acacia Fabace… species APC accepted
#> # ℹ 12 more variables: taxonomic_status_aligned <chr>, aligned_reason <chr>, update_reason <chr>, subclass <chr>,
#> # taxon_distribution <chr>, scientific_name <chr>, taxon_ID <chr>, taxon_ID_genus <chr>, scientific_name_ID <chr>,
#> # canonical_name <chr>, row_number <dbl>, number_of_collapsed_taxa <dbl>
aligned_gbif_taxa |>
update_taxonomy(taxonomic_splits = "collapse_to_higher_taxon",
resources = resources) |>
filter(original_name == "Acacia aneura") # Subsetting Acacia aneura as an example
#> # A tibble: 1 × 21
#> original_name aligned_name accepted_name suggested_name genus family taxon_rank taxonomic_dataset taxonomic_status
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 Acacia aneura Acacia aneura Acacia sp. Acacia sp. [collapse… Acac… Fabac… species APC accepted
#> # ℹ 12 more variables: taxonomic_status_aligned <chr>, aligned_reason <chr>, update_reason <chr>, subclass <chr>,
#> # taxon_distribution <chr>, scientific_name <chr>, taxon_ID <chr>, taxon_ID_genus <chr>, scientific_name_ID <chr>,
#> # canonical_name <chr>, row_number <dbl>, number_of_collapsed_taxa <dbl>Generating lists of synonyms
synonyms_for_accepted_names() compiles a table of all
outdated and misapplied names which once applied to an accepted taxon
name. The output can be in a condensed format, with the synonyms for an
accepted name appearing in a single cell, or in a long format, with a
separate row for each synonym. Both formats indicate each synonyms
“type” - nomenclatural_synonym,
taxonomic_synonym, orthographic_variant,
misapplied, etc. This function is particularly useful for
research applications where you know a currently accepted taxon name and
want to indicate part names that apply, to document the links or to
efficiently search the literature.
> names_to_check <- c("Acacia aneura", "Banksia nivea", "Cardamine gunnii", "Stenocarpus sinuatus")
> synonyms_for_accepted_names(resources = resources, accepted_names = names_to_check, collapse = T)
# A tibble: 4 × 8
# family accepted_name synonyms taxon_rank name_type scientific_name accepted_name_usage_ID genus
# <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#1 Brassicaceae Cardamine gunnii Cardamine hirsuta var. heterophylla (taxonomic synonym); Cardamine hirsuta var. debilis (taxonomic synonym); Cardamine gunnii, ty… species scientif… Cardamine gunn… https://id.biodiversi… Card…
#2 Fabaceae Acacia aneura Acacia aneura var. intermedia (taxonomic synonym); Racosperma aneurum var. intermedium (taxonomic synonym); Acacia aneura var. (N… species scientif… Acacia aneura … https://id.biodiversi… Acac…
#3 Proteaceae Banksia nivea Dryandra nivea var. venosa (taxonomic synonym); Josephia rachidifolia (taxonomic synonym); Dryandra nivea var. adscendens (taxono… species scientif… Banksia nivea … https://id.biodiversi… Bank…
#4 Proteaceae Stenocarpus sinuatus Agnostus sinuatus (taxonomic synonym); Agnostus sinuata (taxonomic synonym); Stenocarpus sinuosus var. intergrifolius (taxonomic … species scientif… Stenocarpus si… https://id.biodiversi… Sten…names_to_check <- c("Acacia aneura", "Banksia nivea", "Cardamine gunnii", "Stenocarpus sinuatus")
> synonyms_for_accepted_names(resources = resources, accepted_names = names_to_check, collapse = F)
# A tibble: 25 × 9
# family accepted_name synonym taxonomic_status taxon_rank name_type scientific_name accepted_name_usage_ID genus
# <chr> <chr> <chr> <fct> <chr> <chr> <chr> <chr> <chr>
# 1 Brassicaceae Cardamine gunnii Cardamine hirsuta var. heterophylla taxonomic synonym species scientific Cardamine gunnii Hewson https://id.biodiversity.org.au/node/apni/2886061 Cardamine
# 2 Brassicaceae Cardamine gunnii Cardamine hirsuta var. debilis taxonomic synonym species scientific Cardamine gunnii Hewson https://id.biodiversity.org.au/node/apni/2886061 Cardamine
# 3 Brassicaceae Cardamine gunnii Cardamine gunnii, type variant nomenclatural synonym species scientific Cardamine gunnii Hewson https://id.biodiversity.org.au/node/apni/2886061 Cardamine
# 4 Brassicaceae Cardamine gunnii Cardamine heterophylla var. heterophylla nomenclatural synonym species scientific Cardamine gunnii Hewson https://id.biodiversity.org.au/node/apni/2886061 Cardamine
# 5 Brassicaceae Cardamine gunnii Cardamine heterophylla nomenclatural synonym species scientific Cardamine gunnii Hewson https://id.biodiversity.org.au/node/apni/2886061 Cardamine
# 6 Brassicaceae Cardamine gunnii Cardamine debilis misapplied species scientific Cardamine gunnii Hewson https://id.biodiversity.org.au/node/apni/2886061 Cardamine
# 7 Fabaceae Acacia aneura Acacia aneura var. intermedia taxonomic synonym species scientific Acacia aneura F.Muell. ex Benth. https://id.biodiversity.org.au/node/apni/6707550 Acacia
# 8 Fabaceae Acacia aneura Racosperma aneurum var. intermedium taxonomic synonym species scientific Acacia aneura F.Muell. ex Benth. https://id.biodiversity.org.au/node/apni/6707550 Acacia
# 9 Fabaceae Acacia aneura Acacia aneura var. (Napperby S.L.Everist 4226) taxonomic synonym species scientific Acacia aneura F.Muell. ex Benth. https://id.biodiversity.org.au/node/apni/6707550 Acacia
# 10 Fabaceae Acacia aneura Acacia aneura var. (Thargomindah D.E.Boyland 8099) taxonomic synonym species scientific Acacia aneura F.Muell. ex Benth. https://id.biodiversity.org.au/node/apni/6707550 Acacia
# ℹ 15 more rows
# ℹ Use `print(n = ...)` to see more rows